
Iris数据获取与应用全攻略:从下载到分类任务实战
在机器学习和数据分析领域,鸢尾花(Iris)数据集堪称经典入门案例。它以其简洁的样本结构、清晰的分类目标和丰富的研究价值,成为算法教学与实验的首选工具。本文将系统讲解Iris数据集的下载途径、使用教程及分类任务实战,并为读者提供安全、高效的应用指南。
一、Iris数据集的核心价值与特点
Iris数据集包含150个样本,每个样本具备4个特征(花萼长宽、花瓣长宽)和1个分类标签(Setosa、Versicolour、Virginica)。其特点可概括为:
二、数据获取途径详解
1. 官方权威渠道
python
from sklearn.datasets import load_iris
iris = load_iris
X, y = iris.data, iris.target
2. 第三方平台资源
三、数据预处理与可视化实战
1. 数据加载与探索
使用Pandas加载本地CSV文件,并添加分类标签:
python
import pandas as pd
df = pd.read_csv('iris.csv', names=['sepal_length','sepal_width','petal_length','petal_width','species'])
print(df.head)
2. 特征分布可视化
通过Seaborn绘制散点矩阵图,直观观察特征间关系:
python
import seaborn as sns
sns.pairplot(df, hue='species', markers=['o','s','D'])
plt.show
![鸢尾花特征散点图示例]
(示例图:不同颜色代表不同类别,横纵轴为特征值)
四、分类任务建模与评估
1. 模型选择与训练
以K近邻算法(KNN)为例,划分训练集与测试集:
python
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
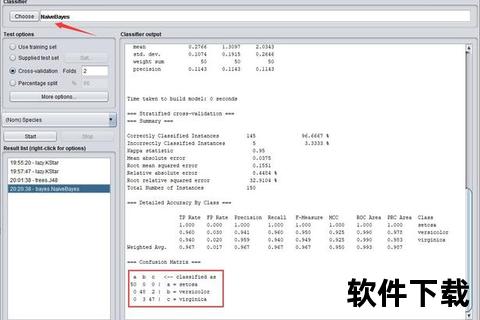
2. 性能评估指标
计算准确率、混淆矩阵等指标:
python
from sklearn.metrics import accuracy_score, confusion_matrix
y_pred = knn.predict(X_test)
print(f"准确率:{accuracy_score(y_test, y_pred):.2%}")
print("混淆矩阵:
confusion_matrix(y_test, y_pred))
输出示例:
准确率:97.78%
混淆矩阵:
[[16 0 0]
[ 0 17 1]
[ 0 0 11]]
五、安全性注意事项与最佳实践
1. 数据来源验证:优先选择UCI、sklearn等权威渠道,避免第三方平台数据篡改。
2. 数据脱敏处理:在医疗等敏感领域应用中,需对特征进行标准化或匿名化处理。
3. 模型泛化能力测试:通过交叉验证(Cross-Validation)确保分类器稳定性。
六、行业应用与未来展望
Iris数据集的应用已从教学扩展到工业领域:
未来,随着AutoML和可解释性AI的发展,Iris数据集或将成为自动化模型调参和决策可视化的典型测试场景。
通过本文的步骤指南,读者可快速掌握Iris数据集的下载方法、分析流程及分类建模技巧。无论是学术研究还是工业应用,这一经典数据集都能为机器学习实践提供坚实的基础。建议结合具体业务场景,进一步探索其在特征选择、模型优化等进阶任务中的应用价值。